

선형 구조 : 자료를 순차적으로 나열한 형태
- 배열
- 연결 리스트
- 스택/큐
비선형 구조 : 하나의 자료 뒤에 다수의 자료가 올 수 있는 형태
- 트리
- 그래프
스택 Stack
- 메모리에 LIFO(Last-In-First-Out)으로 데이터를 저장하는 구조
: 메모리에 가장 나중에 들어간 데이터가 먼저 출력되는형식 - 되돌리기 기능같은 곳에 사용하면 좋겠다.(ctrl+z)
- 따라서 벡터(동적배열)이나 연결리스트 둘중 어느 것으로도 구현할 수 있다.
필요한 기능이
1. 메모리에 데이터 입력하기, 2. 마지막으로 입력된 데이터(맨 뒤에 있는 데이터) 출력하기
2가지 이기 때문.

이건 벡터를 이용해서 stack을 구현한건데,

stack의 타입을 list로만 바꿨음에도 잘 동작한다.
→ 내부적인 구조는 벡터에서 리스트로 바뀌지만, STL container의 장점 : 인터페이스 통일화 로 인해 잘 동작한다.

또한, template 선언에서 type을 Container의 벡터로 기본값을 설정하고,

멤버변수를 container로 지정한 다음,
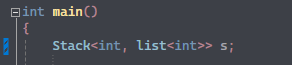
main함수에서 list로 변경도 가능하다.
C++은 왜 top과 pop을 구분?
위 코드를 적다가 생길 수 있는 궁금증인 top과 pop을 구분하는 이유이다.
C#의 경우

이런식으로 마지막 데이터를 ret에 저장하고, _size자체를 감소시키므로서 마지막 데이터를 삭제한 뒤, return 으로 마지막 데이터를 반환한다.
이렇게 구현하지 않는 이유는 순전히 C++의 성능을 유지하기 위해서이다.(예외에 대한 위험도를 낮추기 위해)
가령 T& pop() 으로 선언한다 한들, 애초에 _size를 감소시킬거기 때문에 없는 데이터의 주소를 반환할 수 는 없다.
그래서 무조건 복사하는 방식으로 구현해야한다.
근데 만일 T type의 복사가 매우 무겁고 어려울 상황일 경우, 다양한 예외상황이 있을 경우,
굳이 pop함수에 2가지 기능을 넣어서 구현할 필요가 없다.
그래서 데이터 제거(pop), 데이터 꺼내기(top) 2가지로 나눠서 사용하는 것이다.
큐 Queue
- 메모리에 FIFO(First-In-First-Out)으로 데이터를 저장하는 구조
- 게임 대기열처럼 일반적인 상황에서 많이 쓰임
- 큐는 스택과 다르게 벡터와 리스트 둘다 사용하기 보단 리스트로 구현하는게 매우 좋다. (벡터가 안되는건 아니지만)
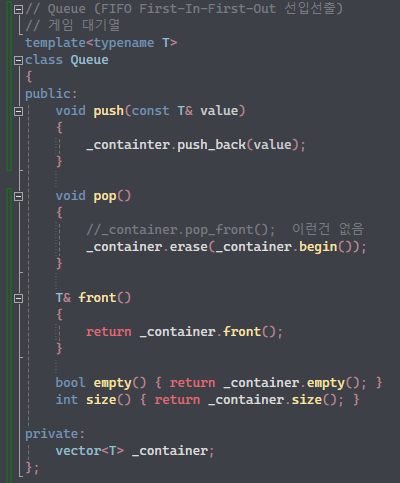
이건 벡터로 큐를 구현한 코드인데,
문제는 pop 부분이다.
애시당초 stack은 LIFO으로 pop은 가장 마지막에 들어온 데이터가 가장 먼저 나감을 의미했기에 pop_back이라는 벡터의 함수를 사용할 수 있었다.
하지만 queue는 FIFO에 의하여 가장 마지막에 들어온 데이터가 가장 나중에 나간다. 즉, 동적배열에서 맨 앞에 있는 데이터(가장 먼저 들어온 데이터)를 삭제하면, 그 뒤에 있는 데이터는 하나씩 주소를 이동해야한다.
front << [1] << [2] << [3] << [4] << [5] << rear(back)
1을 pop
front << [2] << [3] << [4] << [5] << [ ] << rear(back)
그래서 벡터를 이용해서 queue를 구현하기 위해서는 pop_front가 없으므로 begin()으로 첫번째 데이터를 찾아서 erase()로 삭제해주는 것이다. 하지만, 이 방법은 당연하게도 성능에 문제가 생길 수 있다.
하지만, 연결리스트로 구현하면 위의 문제가 모두 사라진다. 그냥 첫번째 노드를 지우고, 2번째 노드와 head를 연결해주면 되기 때문이다.
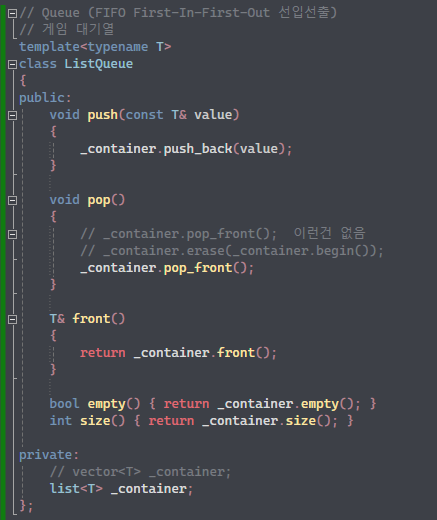
자연스럽게 타입을 list로 만들고 그대로 pop_front를 사용하면 된다.
다만 무조건 큐는 list로 만드느냐? 그건 아니다. 누군가 벡터로 만들라하면 만들어야지;
이 과정은 벡터를 순환하는 방법을 사용해서 큐를 구현할거다.
한마디로, 시작 위치와 끝 위치를 기억하는 것.
[ (front) / (back)][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]
이렇게 배열을 할당받고 idx[0]에 front와 back을 설정한다.
[ 1(front)][ (back) ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]
데이터를 넣으면 이렇게 back이 한칸 위로 이동하고, front에는 1이 들어온다.
[ 1(front)][2][3][4][5][6][7][8][9][10][11][12] [ (back) ] [ ][ ][ ]
그렇게 쭉 넣으면 이런 모양이 되는데
[ ][2 (front) ][3][4][5][6][7][8][9][10][11][12] [ (back) ] [ ][ ][ ]
pop_front를 하면 맨 앞에 있던 데이터 1(가장 먼저 들어온 데이터)이 사라지고, 데이터 2가 있는 메모리가 front가 된다.
즉, 데이터 유효 범위는 front~back-1까지 이다.
그리고 만일
[ ][ ][ ][ ][ ][ ][ ][ ][ ][10 (front) ][11][12][13][14][15][ (back) ]
이렇게 처음에 할당된 배열 끝까지 갔는데 데이터를 더 추가하면?
[17][(back)][ ][ ][ ][ ][ ][ ][ ][10 (front) ][11][12][13][14][15][16]
이렇게 back이 처음 시작한 위치로 돌아가서 또 순환하면 된다.


'개발 > 이론' 카테고리의 다른 글
| 알고리즘 유형2. 구현 feat. 유레카 (0) | 2024.06.25 |
|---|---|
| 알고리즘 유형1. 그리디 (greedy) feat. 유레카 (0) | 2024.06.24 |
| 비선형구조 : 트리 (0) | 2024.04.12 |
| 비선형 구조 : 그래프 DFS, BFS, 다익스트라 (0) | 2024.04.08 |
| 선형 자료구조 기초 (0) | 2024.03.08 |
이것저것 기억하고 싶은거 글쓰는 블로그
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



